




O que pode ser feito com esse subcampo da Inteligência Artificial.
Introdução
A visão computacional faz parte da inteligência artificial (IA), já que busca uma modelagem da visão humana, com a intenção de replicar suas funções, por meio da tecnologia. Permite que computadores e sistemas extraiam informações significativas de imagens digitais, vídeos e outras entradas visuais e ajam ou façam recomendações com base nessas informações. Se a IA permite que os computadores pensem, a visão de máquina permite que eles vejam, observem e entendam.
A visão de máquina funciona muito como a visão humana, exceto pela vantagem que o humano tem uma vida inteira de contexto para treinar como distinguir objetos, a que distância eles estão, se estão se movendo e se há algo errado com uma imagem.
A visão computacional treina as máquinas para executar essas funções, mas precisa fazer isso em muito menos tempo, com câmeras, dados e algoritmos em vez de retinas, nervos ópticos e córtex visual. Entretanto, como um sistema treinado para inspecionar produtos ou visualizar um ativo de produção pode analisar milhares de produtos ou processos por minuto, detectando defeitos ou problemas imperceptíveis, ele pode ultrapassar rapidamente as capacidades humanas. Isso é uma vantagem tremenda!
A visão de máquina é uma das tecnologias fundadoras da automação industrial. Ela ajudou a melhorar a qualidade do produto, acelerar a produção e simplificar a fabricação e a logística por décadas. E agora, essa tecnologia comprovada é combinada com inteligência artificial para liderar a transição para a indústria 4.0.
O que é visão computacional?
A visão computacional é um dos ramos da inteligência artificial e do aprendizado de máquina que busca replicar a capacidade da visão humana, ensinando padrões em algoritmos armazenados em software.
O objetivo da visão computacional não está apenas focado em imitar a visão, mas em ter a percepção do que se vê e entender associando o sentido que o ser humano dá ao que vê.
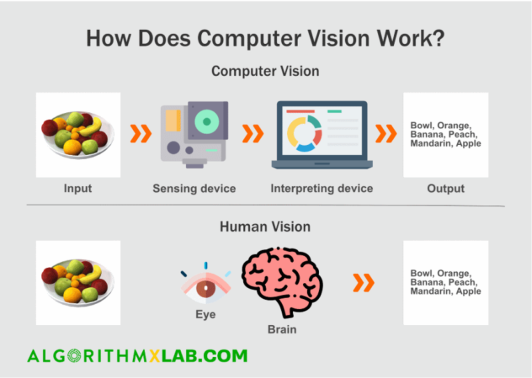
Como funciona a visão computacional?
A tecnologia de Visão Computacional tende a imitar a maneira como o cérebro humano funciona.
Mas como nosso cérebro resolve o reconhecimento visual de objetos? Uma das hipóteses populares afirma que nosso cérebro depende de padrões para decodificar objetos individuais. Este conceito é usado para criar sistemas de visão computacional.
Os algoritmos de Visão Computacional que usamos hoje são baseados no reconhecimento de padrões. Nós treinamos computadores em muitos dados visuais, computadores processam imagens, rotulam os objetos nelas e encontram padrões nesses objetos. Por exemplo, se enviarmos um milhão de imagens de flores, o computador as analisará, identificará padrões semelhantes a todas as flores e, ao final desse processo, criará um modelo de “flor”. Como resultado, o computador será capaz de detectar com precisão se uma determinada imagem é uma flor cada vez que enviarmos imagens para ela.
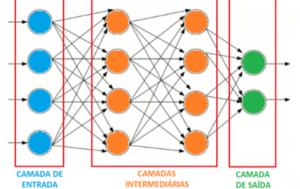
Os métodos e técnicas de Deep Learning transformaram profundamente a Visão Computacional, juntamente com outras áreas da Inteligência Artificial, a tal ponto que para muitas tarefas seu uso é considerado padrão. Em particular, as redes neurais convolucionais (CNNs) alcançaram resultados além do estado da arte usando técnicas tradicionais de Visão Computacional.
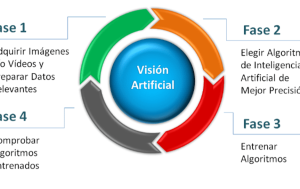
TRADUÇÃO: Fase 1 – Adquirir imagens e/ou vídeos e preparar dados relevantes.
Fase 3 – Treinar os algoritmos.
Fase 4 – Comprovar os algoritmos treinados.
Abaixo estão listadas quatro etapas que descrevem uma abordagem geral para a construção de um modelo de Visão Computacional usando redes neurais convolucionais (CNNs):
- Crie um conjunto de dados composto de imagens anotadas ou use um existente. As anotações podem ser a categoria da imagem, para um problema de classificação, pares e classes de caixas delimitadoras, para um problema de detecção de objetos, ou uma segmentação de pixels de cada objeto de interesse presente em uma imagem, para problemas de segmentação, por exemplo.
- Extraia, de cada imagem, as características relevantes para a tarefa em questão. Este é um ponto chave na modelagem do problema. Por exemplo, as características usadas para reconhecer rostos, características baseadas em critérios faciais, obviamente não são as mesmas usadas para reconhecer atrações turísticas ou órgãos humanos.
- Treine um modelo de Deep Learning com base nas características isoladas. Treinar significa alimentar o modelo de aprendizado de máquina com muitas imagens e ele aprenderá, com base nessas características, como resolver a tarefa em questão.
- Avalie o modelo usando imagens que não foram usadas na fase de treinamento. Ao fazer isso, a precisão do modelo de treinamento pode ser testada.
A estratégia é simples, mas serve bem ao propósito. Essa abordagem, conhecida como Aprendizado Supervisionado, requer um conjunto de dados que englobe o fenômeno que o modelo precisa aprender.
Modelo de redes neurais convolucionais (CNNs):
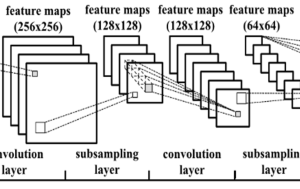
Exemplos de aplicação de visão computacional
- Reconhecimento facial com software que temos hoje em mãos com nossos próprios celulares para desbloquear com o rosto, associação automática de rostos em nossos aplicativos de fotos.
- Reconhecimento de objetos, com sua classificação e estabelecimento de coordenadas que tem permitido avançar na aplicação de veículos autônomos.
- Identificação de doenças e seu estado, através de imagens médicas diagnósticas, ajudando assim a determinar a presença ou ausência de células cancerígenas, danos pulmonares, entre outros.
- Classificação de imagens. Um exemplo prático que você pode fazer nessa hora é acessar o Google imagem e carregar uma imagem específica do seu computador, a rede neural em questão de segundos irá associar imagens relacionadas ou até mesmo a mesma se for encontrada na rede.
Abaixo um exemplo do IBM Insights mostra como ocorre a detecção de objetos. O conjunto de dados é criado ao extrair frames de um vídeo. Observe que os carros são identificados manualmente em uma seleção de frames ao arrastar uma caixa em volta de cada um. Depois de um pouco de rotulagem manual, a autorrotulagem e o aumento de dados são usados para multiplicar seus esforços manuais.
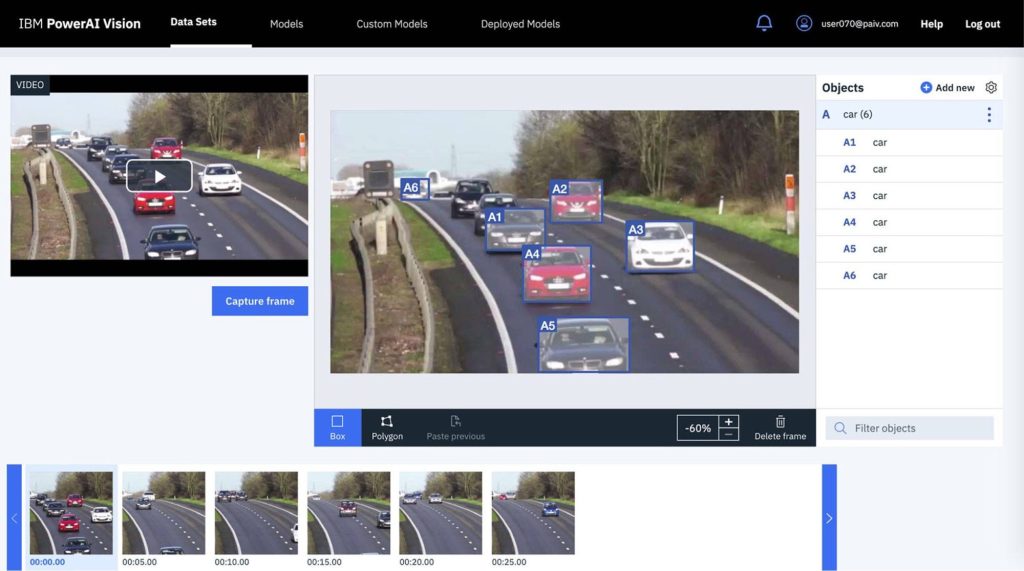
Aplicações da visão computacional
Há muita pesquisa sendo realizada no campo da visão computacional. Os aplicativos do mundo real demonstram a importância da visão de máquina em aplicativos para negócios, entretenimento, transporte, saúde e tarefas diárias. Um dos principais impulsionadores do crescimento desses aplicativos é a enxurrada de informações visuais geradas por smartphones, sistemas de segurança, câmeras de trânsito e outros dispositivos com instrumentação visual. Com esses dados, é possível desempenhar um papel mais proeminente em diferentes setores, mas atualmente não são usados. A informação cria um banco de teste para aplicações de visão de máquina de treinamento e uma plataforma de lançamento para sua integração em várias atividades humanas, veja alguns exemplos de aplicação:
- A gigante IBM usou visão de máquina para criar My Moments para o torneio de golfe Masters de 2018. IBM Watson visualizou centenas de horas de filmagens do Masters e foi capaz de selecionar as melhores tacadas através das cenas e sons. Ele organizou esses momentos-chave e os apresentou aos seguidores.
- O Google Tradutor permite que os usuários obtenham a tradução para outro idioma quase instantaneamente, basta apontar a câmera de um smartphone para o texto que deseja traduzir e selecionar o idioma.
- O desenvolvimento de veículos autônomos depende da visão de máquina para entender a entrada visual das câmeras e outros sensores de um carro. É essencial identificar outros veículos, sinais de trânsito, marcações de faixa, pedestres, bicicletas e outras informações visuais encontradas na via.
- A IBM está aplicando a tecnologia de visão de máquina com alguns de seus parceiros, como a Verizon, para aplicar IA inteligente à computação de ponta e ajudar as montadoras a identificar defeitos de qualidade antes que um veículo saia da fábrica.
Vantagens de aplicar visão computacional
Existem grandes vantagens inerentes à aplicação da visão computacional para a gestão ou execução de processos em qualquer negócio, entre elas:
- Grande capacidade de automação em tarefas complexas.
- Solução para atividades repetitivas.
- Maior segurança na utilização de equipamentos industriais.
- Facilidade de aprendizado e uso.
- Posicionamento de marca.
- Inovação.
- Permitem atingir níveis muito elevados de controle de qualidade.
- Detecção instantânea de defeitos.
- Detecção milimétrica para orientar as atividades com a máxima precisão.
- Inspeção de superfícies de máxima demanda.
A capacidade de “ver” torna-se tão útil para os equipamentos industriais quanto para qualquer ser vivo, já que a tomada de decisão inteligente decorre dessa propriedade, baseada em dados que podem mudar ao longo do tempo.
Devido à visão computacional, os equipamentos tecnológicos estão cada vez mais versáteis, eficazes e próximos da visão do modelo ideal de produção 4.0.
O futuro está só começando
As máquinas já podiam “ver” antes da IA e do aprendizado de máquina. Essa mudança, de máquinas capazes de automatizar tarefas simples para máquinas autônomas capazes de ver além do que o olho humano pode ver e pensar por si mesmas para otimizar elementos por períodos mais longos, impulsionará novos níveis de inovação industrial.
Pode parecer ficção científica, mas a visão de máquina inteligente já está funcionando nas fábricas, armazéns e centros de expedição de hoje, auxiliando e ajudando os trabalhadores humanos nas tarefas mais mundanas para que possam colocar suas habilidades em prática.
A visão de máquina e a automação industrial oferecem dividendos imediatos na forma de aumentos de produtividade, controles de qualidade mais rígidos e maior eficiência. Como elemento fundamental nas tecnologias da Indústria 4.0, a visão de máquina está transformando a manufatura, a logística e as operações.


